구글이 Gemini 2.5 Flash Native Audio 모델을 새롭게 공개하면서, 이를 기반으로 한 구글 앱들도 함께 업그레이드되었다는 소식이 전해졌다.
https://blog.google/products/gemini/gemini-audio-model-updates
기존의 음성 기반 AI 대화 방식은 다단계 처리 구조였다.
즉, 사용자의 음성을 먼저 텍스트로 변환하고, 텍스트 상태에서 사고한 뒤, 다시 음성으로 변환하여 들려주는 방식이었다. 하지만 Native Audio 모델이 적용되면서 이 구조가 완전히 바뀌었다.
- 기존 방식: Audio In → Text → Text → Audio Out
- 새로운 방식: Audio In → Audio Out
이제는 음성을 텍스트로 변환하지 않고, 음성 자체를 직접 이해한다.
말의 내용뿐 아니라 톤, 감정, 말의 속도까지 포함해 인식하고, 그에 맞는 음성 응답을 바로 생성한다.
이 변화로 가장 크게 체감되는 부분은 Latency(지연 시간)다.
지연이 획기적으로 줄어들면서, 그동안 기술적으로 어렵다고 여겨졌던 실시간 동시 통역이 현실적인 수준으로 올라왔다.
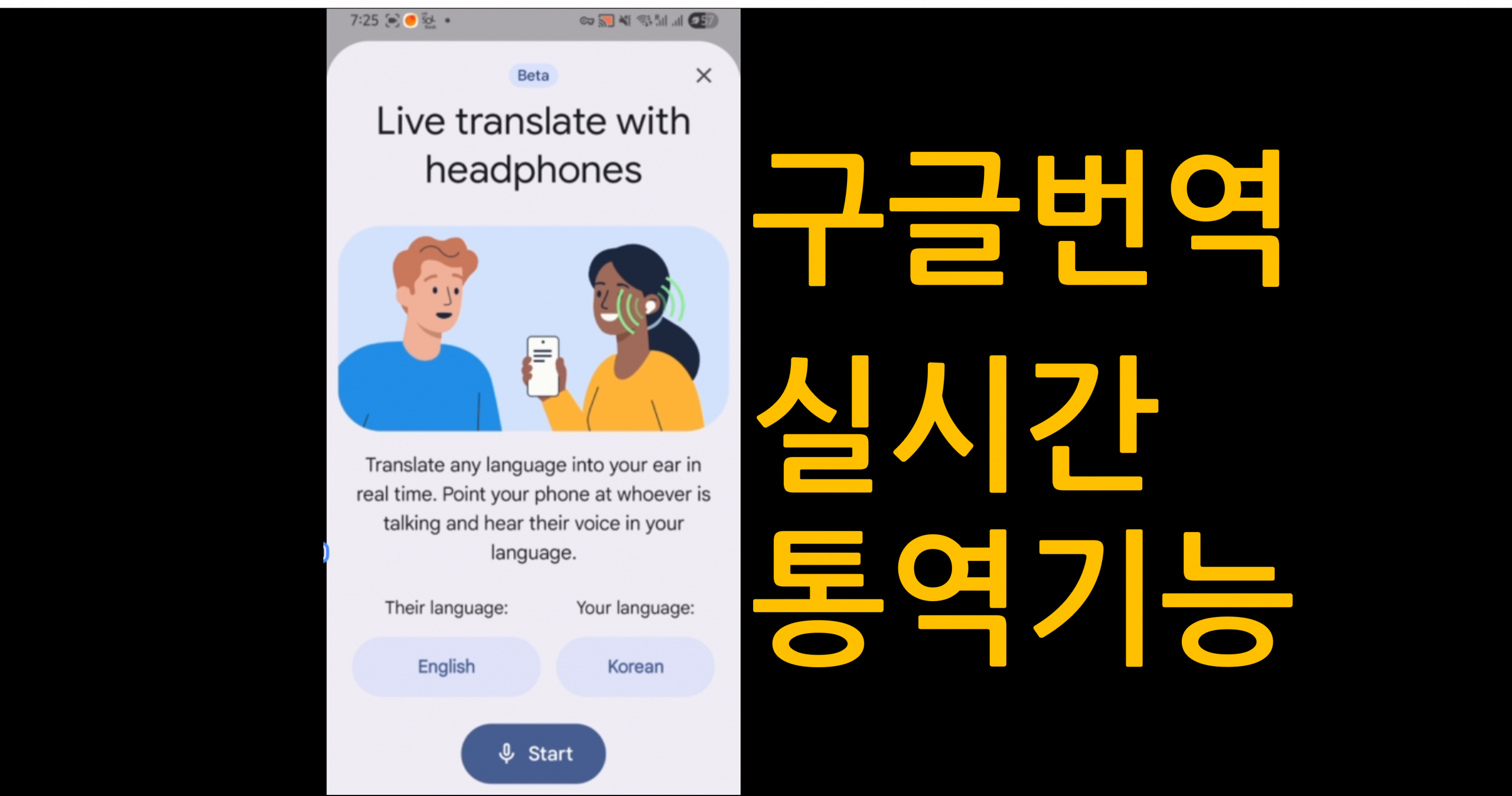
이 기능은 현재 Google Translate에 베타 기능으로 추가되었으며, 미국·멕시코·인도 지역에서는 헤드폰을 착용한 상태로 Google Translate를 실행하면, 상대방의 말을 실시간으로 통역해 바로 귀로 들을 수 있다.
통시 통역가가 더 이상 필요하지 않을 수도 있겠다.
지금 내가 있는 곳에서는 사용할 수 가 없어, VPN등, 몇 가지 설정을 통해 나 역시 이 최신 기능을 직접 테스트해볼 수 있었는데, 결과는 솔직히 말해 소름이 돋을 정도였다.
가장 먼저 떠오른 생각은 이것이었다.
과연 동시통역가라는 직업이 앞으로 필요할까?
물론 매우 중요하고 민감한 자리에서는 여전히 사람이 필요할 것이다. 하지만 단순한 동시 통역이 요구되는 행사나 컨퍼런스 현장이라면, 기술적으로는 이미 충분히 대체 가능한 수준에 도달했다는 인상을 받았다.
두 번째로 든 생각은, 삼성이 갤럭시 AI의 핵심 기능으로 내세우고 있는 Live Translate가 쉽지 않겠다는 점이었다. 삼성은 자체적인 소프트웨어·AI 생태계가 없는 상태에서 하드웨어 중심으로 AI 기능을 얹어 차별화를 시도하고 있지만, 이러한 변화는 분명 위기감을 키울 수밖에 없어 보인다.
좀 더 테스트 결과를 이야기 하면
테스트 결과를 조금 더 구체적으로 말하자면,
- 영어 → 한국어
- 일본어 → 한국어
이 두 가지 조합을 테스트했는데, 모두 매우 인상적인 결과를 보여주었다.
화자가 여러 명일 경우, 각기 다른 목소리로 구분해주었고, 말의 속도도 자연스럽게 조절되었으며, 무엇보다 말의 톤과 분위기까지 어느 정도 살려서 전달하려는 시도가 느껴졌다.
다만, 영어와 한국어·일본어는 문법 구조가 크게 다른 언어이다 보니, 일부 문장에서는 도치된 형태로 번역되는 느낌을 받는 경우도 있었다.
새로운 비즈니스 시장의 가능성
이 경험을 통해 또 하나 떠오른 생각은, 특정 산업이나 특수 상황에서 동시 통역이 필요하다면 해당 모델을 파인튜닝해 전문화된 통역 모델을 만드는 것도 충분히 가능하겠구나라는 점이었다.
더 나아가, 스마트폰과 연동해 사용하는 동시 통역 전용 액세서리 시장도 열릴 수 있겠다는 생각이 들었다. 예를 들어, Bluetooth 멀티 액세스 포인트 방식으로 여러 명이 동시에 통역 음성을 들을 수 있는 헤드셋이나 이어버드 같은 형태 말이다.
아직 아시아 지역에서는 인도를 제외하고 최신 Google Translate 기능을 사용할 수 없고, 정식 확장은 2026년으로 예정되어 있다. 그래서인지, 내년이 더욱 기대되는 이유가 하나 더 생겼다.
아쉽게도 개인 장난감으로 진행 중인 실시간 번역 툴 개발은 중단(Drop) 하기로 했다.
기술은 생각보다 훨씬 빠르게, 그리고 조용히 판을 바꾸고 있었다.
Leave a Reply